이 글은 주니어 백엔드 개발자가 반드시 알아야 할 핵심 지식을 기반으로 작성되었습니다.
public boolean login(String id, String password) {
Optional<User> opt = findUser(id); // 1. User 조회
if (opt.isEmpty()) { // 2. User가 없으면 false 리턴
return false;
}
User u = opt.get();
if (!u.matchPassword(password)) { // 3. 암호가 일치하지 않으면 false 리턴
return false;
}
PointResult result = pointClient.giveLoginPoint(id); // 4. 포인트 지급 서비스 호출
if (result.isFailed()) { // 5. 포인트 지급에 실패하면 익셉션 발생
throw new PointException();
}
appendLoginHistory(id); // 6. 로그인 내역 추가
return true;
}- 위의 코드는 전형적인 동기 방식을 따릅니다.
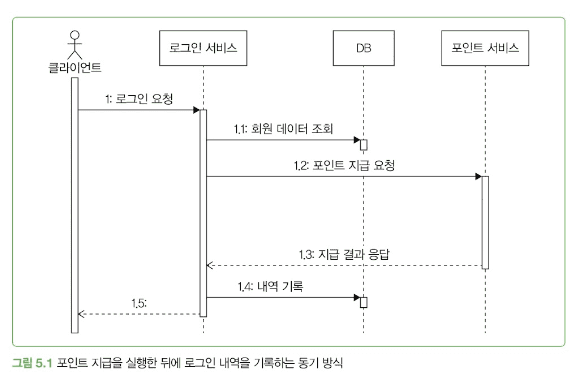
동기 방식의 외부 연동 고려사항
동기 방식에서 외부 연동 실패가 전체 기능의 실패인지 확인 필요
문제 상황
앞선 예에서는 포인트 지급 서비스 연동에 실패하면 로그인에도 실패한다고 가정했습니다.
포인트 서비스 장애 시 로그인까지 막힐 필요가 있을까요?
해결 방안
아마도 그렇지 않을 것입니다. 포인트 지급에 실패하더라도:
- 로그인 자체는 정상적으로 동작해야 합니다
- 나머지 기능을 사용할 수 있어야 합니다
포인트 지급 실패 시 후처리용 로그를 남기고 로그인은 성공 처리
개선된 로그인 코드
public boolean login(String id, String password) {
Optional<User> opt = findUser(id); // 1. User 조회
if (opt.isEmpty()) { // 2. User가 없으면 false 리턴
return false;
}
User u = opt.get();
if (!u.matchPassword(password)) { // 3. 암호가 일치하지 않으면 false 리턴
return false;
}
PointResult result = pointClient.giveLoginPoint(id); // 4. 포인트 지급 서비스 호출
if (result.isFailed()) { // 5. 포인트 지급에 실패하면 후처리 위해 내역 남김
recordPointFailure(id, result);
}
appendLoginHistory(id); // 6. 로그인 내역 추가
return true;
}외부 서비스 응답 시간 고려사항
외부 서비스 응답이 느리면 전체 응답도 느려짐
비동기 방식 도입의 필요성
외부 연동 결과가 즉시 필요하지 않다면 비동기 처리 고려
비동기(Asynchronous) 방식의 특징
- 한 작업이 끝날 때까지 기다리지 않고 바로 다음 작업을 처리
- 비동기 방식을 사용하면 외부 연동이 끝날 때까지 기다리지 않고 바로 다음 작업을 진행할 수 있습니다
포인트 지급을 기다리지 않고 로그인 즉시 성공 응답 → 사용자 응답 속도 향상
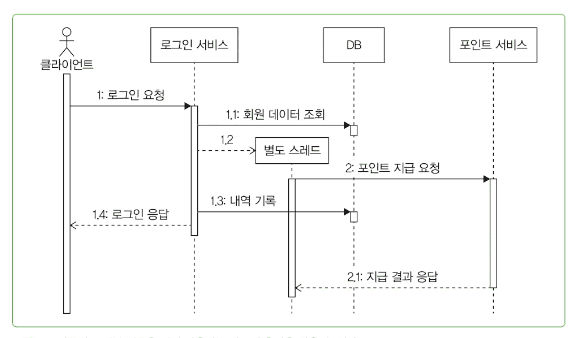
비동기 방식의 장점
포인트 서비스에 일시적으로 문제가 생겨 포인트 지급 처리에 시간이 오래 걸려도 로그인 서비스의 응답 시간은 증가하지 않습니다. 사용자는 평소처럼 로그인에 성공하고 서비스를 사용할 수 있습니다. 단지 포인트가 평소보다 조금 늦게 지급될 뿐입니다.
사용자는 빠른 로그인 후 서비스 사용을 선호
비동기 방식 적용 가능한 연동 예시
생각보다 많은 연동에서 비동기 방식을 사용해도 됩니다. 다음은 비동기 방식으로 연동해도 크게 문제가 되지 않는 몇 가지 예입니다:
- 쇼핑몰에서 주문이 들어오면 판매자에게 푸시 보내기 (푸시 서비스 연동)
- 학습을 완료하면 학생에게 포인트 지급 (포인트 서비스 연동)
- 컨텐츠를 등록할 때 검색 서비스에도 등록 (검색 서비스 연동)
- 인증번호를 요청하면 SMS로 인증 메시지 발송 (SMS 발송 서비스 연동)
비동기 연동 가능 조건 - 4가지 특징
이 예시들에는 몇 가지 공통적인 특징이 있다:
1. 시차가 허용되는 경우
시차 허용
- 주문 후 1분 뒤 푸시 발송 → 판매 지장 없음
- 컨텐츠 등록 후 10초 뒤 검색 노출 → 문제 없음
2. 재시도가 가능한 경우
재시도 가능
- 푸시 실패 → 재시도로 해결
- 포인트 지급 실패 → 몇 초 후 재시도
- SMS 미수신 → "다시 받기" 기능
3. 수동 처리가 가능한 경우
수동 처리
- 검색 연동 실패 → 관리자가 수동으로 재등록
4. 실패를 무시할 수 있는 경우
실패 무시 가능
- 주문 알림 푸시 실패 → 판매 지장 없음
- 일부 컨텐츠 검색 불가 → 서비스 계속 가능
실제 적용 사례
4가지 특징 중 하나라도 해당 → 비동기 처리 검토
실제 비동기로 외부 연동을 처리한 사례:
- 포인트 지급: 사용자가 미션을 달성하면 포인트를 지급하는데 포인트 서비스와의 연동을 비동기로 처리했다
- 주문 정보 동기화: 주문 시스템에 생성된 주문 정보를 회원 관리 시스템에 반영할 때 비동기로 동기화했다
- 택배사에 집하 요청: 회원이 쇼핑몰에서 물건을 주문하면 택배사에 집하 요청을 하는데 비동기로 집하 요청 데이터를 전송했다
비동기 연동 구현 방식
비동기 연동은 다양한 방식으로 구현할 수 있다. 이 책에서는 다음의 5가지 방식에 대해 살펴볼 것이다:
- 별도 스레드로 실행하기
- 메시징 시스템 이용하기
- 트랜잭션 아웃박스 패턴 사용하기
- 배치로 연동하기
- CDC 이용하기
이 5가지 방식만 알아도 대부분의 비동기 연동 구현 가능
1. 별도 스레드로 실행
1. new Thread() 사용
가장 간단한 방법으로 새로운 스레드를 생성하여 비동기로 실행하는 방법입니다.
public class OrderService {
private final PushClient pushClient;
public OrderResult placeOrder(OrderRequest req) {
// 주문 생성 처리
Order order = createOrder(req);
// 별도 스레드에서 푸시 발송
new Thread(() -> {
pushClient.sendPush(pushData);
}).start();
return successResult(order); // 푸시 발송을 기다리지 않고 리턴
}
}2. ThreadPool 사용
매번 새로운 스레드를 생성하는 대신 스레드 풀을 사용하여 성능을 개선할 수 있습니다.
public class OrderService {
private final PushClient pushClient;
private final ExecutorService executor = Executors.newFixedThreadPool(50);
public OrderResult placeOrder(OrderRequest req) {
// 주문 생성 처리
Order order = createOrder(req);
// 스레드 풀에 푸시 발송 작업 제출
executor.submit(() -> {
pushClient.sendPush(pushData);
});
return successResult(order); // 푸시 발송을 기다리지 않고 리턴
}
}3. @Async 어노테이션 사용
Spring Framework에서 제공하는 @Async 어노테이션을 사용하여 더 간편하게 비동기 실행할 수 있습니다.
@Service
public class PushService {
@Async
public void sendPushAsync(PushData pushData) {
pushClient.sendPush(pushData);
// ... 기타 코드
}
}
@Service
public class OrderService {
private final PushService pushService;
public OrderResult placeOrder(OrderRequest req) {
// 주문 생성 처리
Order order = createOrder(req);
// 비동기로 푸시 발송
pushService.sendPushAsync(pushData);
return successResult(order); // 푸시 발송을 기다리지 않고 리턴
}
}Async 주의사항
@Async 사용 시 메서드명에 "Async" 포함 권장
pushService.sendPushAsync(pushData)비동기 메서드는 호출 측 try-catch 블록이 작동 안 함
// 잘못된 예외 처리
public OrderResult placeOrder(OrderRequest req) {
try {
pushService.sendPushAsync(pushData); // 비동기 실행
} catch(Exception ex) {
// sendPushAsync()가 비동기로 실행되므로 catch 블록은 동작하지 않는다.
// 에러 처리 코드
}
return successResult(...);
}
// 올바른 예외 처리
@Async
public void sendPushAsync(PushData pushData) {
try {
pushClient.sendPush(pushData);
} catch(Exception e) {
// 재시도 로직
try {
Thread.sleep(500);
} catch(Exception ex) {}
try {
pushClient.sendPush(pushData); // 재시도
} catch(Exception e1) {
// 실패를 로그로 남기거나
log.error("Push 발송 실패", e1);
}
}
}비동기 메서드 예외는 트랜잭션 롤백에 영향 없음
스레드와 메모리 고려사항
- 각 스레드는 메모리를 소모합니다 (예: 256KB)
- 100,000개의 스레드를 생성하면 약 24GB의 메모리가 필요할 수 있습니다
- 스레드 생성 시간과 스케줄링으로 인한 CPU 시간 소모가 큽니다
- 스레드 풀을 사용하여 고정된 수의 스레드를 유지하는 것이 좋습니다
- 네트워크 I/O 작업의 경우 가상 스레드(Java) 또는 고루틴(Go) 사용을 권장합니다
2. 메시징 시스템 이용
메시징 시스템의 개념과 장점
메시징 시스템은 시스템 간 직접 호출 대신 중간에 메시징 시스템을 두어 데이터를 전달하는 방식입니다.
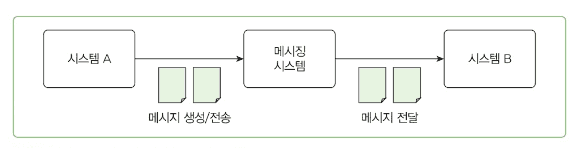
디커플링
- 시스템 A와 시스템 B가 직접 연결되지 않음
- 시스템 B의 성능 저하가 시스템 A에 영향을 주지 않음
- 메시징 시스템이 버퍼 역할을 하여 시스템 B가 자신의 속도로 메시지를 처리할 수 있음
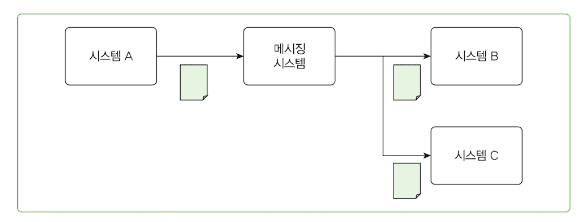
확장성
- 새로운 시스템 추가 시 기존 시스템 수정 없이 메시징 시스템에만 연결
- 예: 시스템 A가 시스템 C에도 데이터를 전송해야 할 때, 시스템 A 코드 수정 없이 시스템 C만 메시징 시스템에 연결
메시징 시스템 기술 비교
이 책을 쓰는 시점을 기준으로 메시징 시스템 용도로 많이 사용되는 기술은 카프카, 래빗MQ, 레디스 pub/sub 등이 있음. 각 기술은 서로 다른 특징을 가지고 있으므로, 사용 목적에 맞는 기술을 선택해야 함.
Kafka 특징
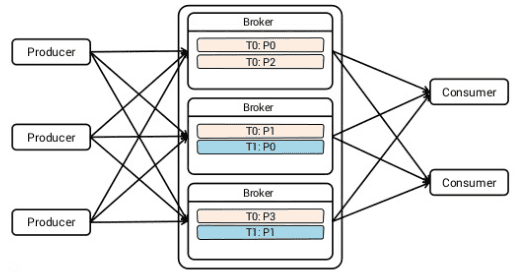
- 높은 처리량을 자랑함 - 초당 백만 개 이상의 메시지를 처리할 수 있음
- 수평 확장이 용이함 - 서버(브로커), 파티션, 소비자를 늘리면 됨
- 메시지를 파일에 보관해서 메시지가 유실되지 않음
- 파티션 단위로 순서를 보장함 - 하지만 토픽 수준에서는 순서를 보장할 수 없음
- 예: "주문" 토픽에 파티션 2개가 있고, A고객이 주문 3개(1→2→3)를 연속으로 넣었을 때
- 파티션0: 주문1, 주문3 (순서 보장됨)
- 파티션1: 주문2 (순서 보장됨)
- 소비자가 받는 순서: 주문2 → 주문1 → 주문3 (순서가 뒤바뀔 수 있음)
- 예: "주문" 토픽에 파티션 2개가 있고, A고객이 주문 3개(1→2→3)를 연속으로 넣었을 때
- 소비자는 메시지를 언제든지 재처리할 수 있음
- Pull 모델을 사용함 - 소비자가 카프카 브로커에서 메시지를 읽어가는 방식
RabbitMQ 특징
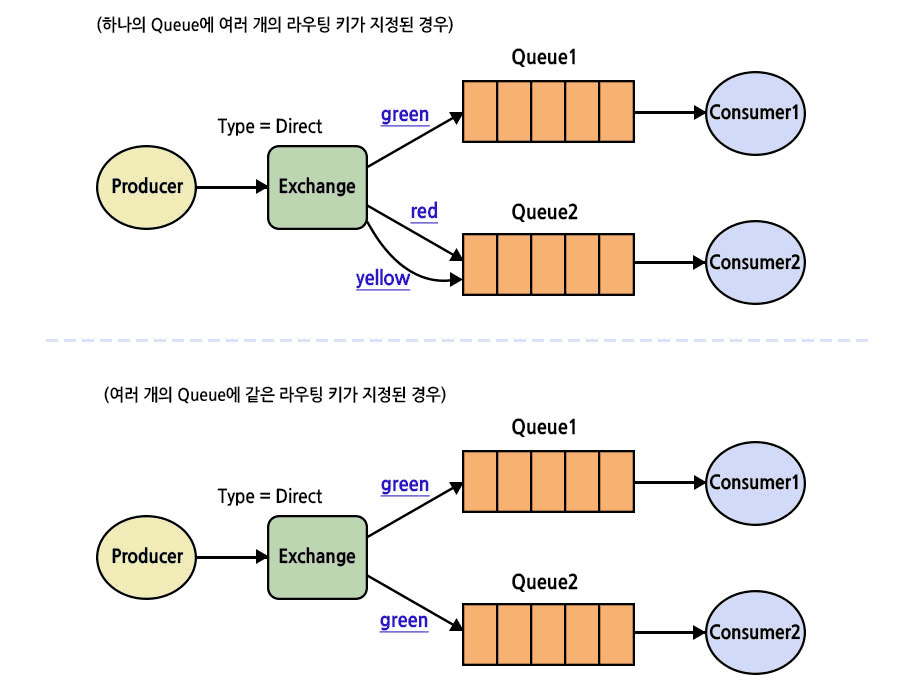
- 클러스터를 통해 처리량을 높일 수 있음 - 단, 카프카보다 더 많은 자원을 필요로 함
- 메모리에만 메시지를 보관하는 큐 설정을 사용하면 장애 상황 시 메시지가 유실될 수 있음
- 메시지는 큐에 등록된 순서대로 소비자에 전송됨
- 메시지가 소비자에 전달됐는지 확인하는 기능을 제공함
- Push 모델을 사용함 - 래빗MQ 브로커가 소비자에 메시지를 전송함. 소비자의 성능이 느려지면 큐에 과부하가 걸려 전반적으로 성능 저하가 발생할 수 있음
- 다재다능함 - AMQP, STOMP 등 여러 프로토콜을 지원하고, 게시/구독 패턴뿐만 아니라 요청/응답, 점대점(point-to-point) 패턴을 지원함. 또한 우선순위를 지정해서 처리 순서를 변경할 수도 있음
Redis pub/sub 특징
- 메모리를 사용하므로 지연 시간이 짧고, 래빗MQ 대비 처리량이 높음
- 구독자가 없으면 메시지가 유실됨
- 기본적으로 영구 메시지를 지원하지 않음
- 모델이 단순해서 사용하기 쉬움
기술 선택 가이드
- 메시지가 유실되어도 상관없다면 레디스 pub/sub 기능을 고려함 - 카프카나 래빗MQ에 비해 사용법이 간단하고, 적은 장비로 높은 성능을 낼 수 있음
- 트래픽이 대량으로 발생한다면 카프카를 고려함 - 여기서 말하는 대량 트래픽은 초당 수십만에서 수백만 이상의 메시지를 말함
- 트래픽 규모가 크지 않고 메시지를 정확하게 순서대로 소비자에 전달해야 하거나 AMQP나 STOMP 프로토콜로 연동해야 한다면 래빗MQ를 고려함
메시지 생성 측 고려 사항
메시지 유실 처리 방법
메시지를 생성할 때 고려할 점은 메시지 유실에 대한 것임. 예를 들어 메시지 전송 과정에서 타임아웃이 발생할 수 있음. 타임아웃 문제는 생산자와 메시징 시스템 간의 네트워크 연결이 불안정하면 언제든지 발생할 수 있음.
오류 처리를 위해 선택할 수 있는 방법 3가지:
1. 무시함
- 오류를 무시.
- 메시지의 용도에 따라 유실이 일부 허용될 수 있음
- 단순 로그 메시지: 유실되어도 괜찮음. 나중에 로그를 조회할 때 로그가 없으면 아쉬울 수 있지만 기능 동작에 문제는 없음 -> 무시해도 기능상 이상이 없으면 무시 가능
2. 재시도함
- 일시적인 네트워크 불안정과 같은 오류는 재시도를 통해 해결될 수 있음
- 주의사항: 메시지 전송을 재시도하는 과정에서 중복된 메시지가 전송될 수 있음
- 실제로는 전송에 성공했는데 일시적인 네트워크 오류로 전송에 실패한 것으로 인지하고 재시도할 수 있기 때문 -> 메시지마다 고유 식별자를 사용
3. 실패 로그를 남김
- 단순히 실패 로그를 남기는 것임. 로그는 나중에 후처리를 하는 데 사용됨
- 실패 로그는 DB에 저장할 수도 있고 파일에 남길 수도 있음
- 실패 로그는 후처리에 필요한 데이터를 담고 있어야 함
DB 트랜잭션 연동 고려
메시지 생산자는 DB 트랜잭션과의 연동도 고려해야 함. DB 트랜잭션에 실패했는데 메시지가 발송되면 잘못된 데이터가 전달될 수 있기 때문임
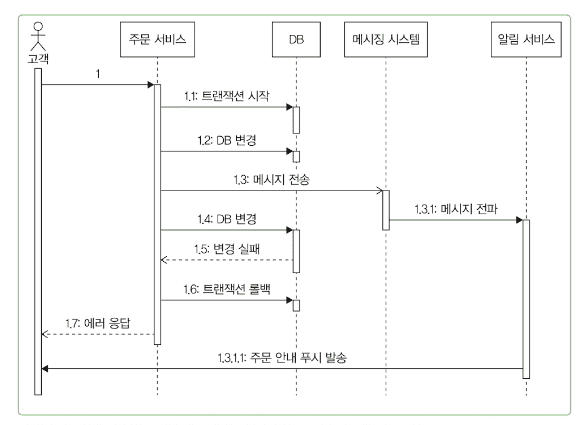
- 주문이 완료 됐다는 푸시 알림 발송
- 변경 실패 -> 트랜잭션 롤백
- 고객은 실패 화면을 보는데 주문 알림 푸시 알림을 받게됨
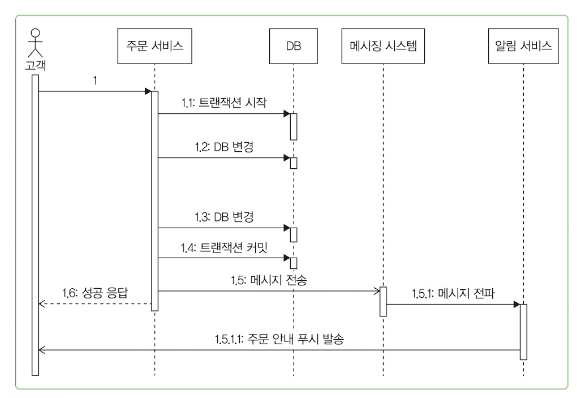
-> 트랜잭션이 끝난 뒤에 메시지를 전송
글로벌 트랜잭션
- 개념: 여러 데이터베이스를 하나의 트랜잭션으로 처리
- 알고리즘: 2-Phase Commit (2PC)
- 장단점:
- 장점: DB 변경과 메시지 전송을 하나의 트랜잭션으로 묶음
- 단점: 성능 저하, 모든 메시징 시스템이 지원하지 않음
메시지 소비 측 고려사항
1. 중복 메시지 처리
고유 메시지 ID 활용
while(true) {
ConsumerRecords<String, String> records consumer.poll(Duration.ofMillis(100));
for(ConsumerRecord<String, String> record: records){
Message m = messageConverter.convert(record.value());
if (checkAlreadyHandled(m.getId())) { // 이미 처리했는지 확인
continue; // 처리하지 않고 무시함
}
handle(m);
recordHandledLog(m.getId()); // 처리 여부 기록
}
}2. 멱등성 보장
메시지 처리 실패 후 재수신 시 중복 처리 가능성 주의
문제 상황:
- 외부 API를 호출했을 때 읽기 타임아웃이 발생하면 성공했을 가능성이 있음
- 실제로 성공했다면 수신자는 외부 API를 중복해서 두 번 호출하게 됨
-> 멱등성을 갖도록 API를 구현
3. 모니터링의 중요성
중복 메시지 처리와 함께 메시지 소비자를 구현할 때 고려할 점은 메시지를 잘 소비하고 있는지 모니터링하는 것임
문제 상황:
- 메시지 소비자의 처리 속도가 갑자기 느려지면 큐에 메시지가 계속 쌓이게 됨
- 메시징 시스템에 따라 큐가 가득 차면 생산자가 메시지를 큐에 넣지 못하게 막는 상황도 발생할 수 있음
메세지 종류
| 이벤트 | 커맨드 |
|---|---|
| 주문함 | 포인트 지급하기 |
| 로그인에 실패함 | 로그인 차단하기 |
| 상품 정보를 조회함 | 배송 완료 문자 발송하기 |
| 배송을 완료함 |
이벤트 특징:
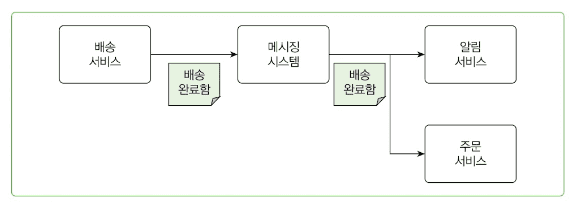
- 과거에 일어난 일을 나타냄 (과거형 표현)
- "~했다", "~됐다" 형태
- 시스템에서 발생한 사실을 알림
- 여러 시스템이 구독하여 반응할 수 있음
커맨드 특징:
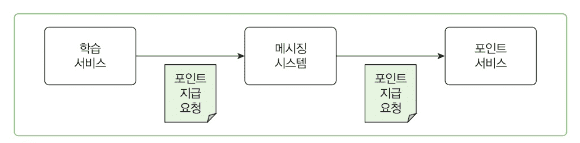
- 앞으로 실행할 작업을 나타냄 (명령형 표현)
- "~하기", "~하라" 형태
- 특정 작업의 수행을 요청
- 보통 하나의 시스템이 처리함
궁극적 일관성
개념
- 분산 시스템에서 데이터 복제를 다루는 일관성 모델
- 두 데이터 저장소 간 일관성을 보장하지만 즉시는 아님
- "일정 시간 후에" 일관성 달성
예시
- 배송기사: 배송 완료! (배송 시스템에 기록)
- 고객 앱: 아직 "배송 중"으로 표시 (몇 분 지연)
- 최종: 메시지 전달 후 고객 앱도 "배송 완료"로 변경
3. 트랜잭션 아웃박스 패턴 사용
트랜잭션 아웃박스 패턴의 개념
트랜잭션 완료 후 메시지 전송 방식도 완벽하지 않음. **재시도와 에러 처리 로직을 구현해도 메시징 시스템 연동 자체가 실패할 수 있기 때문
트랜잭션 아웃박스 패턴의 핵심 아이디어:
- 메시지 데이터를 먼저 데이터베이스에 안전하게 저장
- 별도 메세지 중계 프로세스가 저장된 메시지를 읽어서 메시징 시스템에 전송
public void 주문처리() {
transaction.begin();
try {
// 1. 주문 데이터 저장
orderRepository.save(order);
// 2. 메시지도 DB에 함께 저장 (같은 트랜잭션)
outboxRepository.save(new OutboxMessage("주문완료", orderData));
// 3. 둘 다 성공하면 커밋
transaction.commit();
} catch (Exception e) {
transaction.rollback(); // 둘 다 실패하면 롤백
}
}
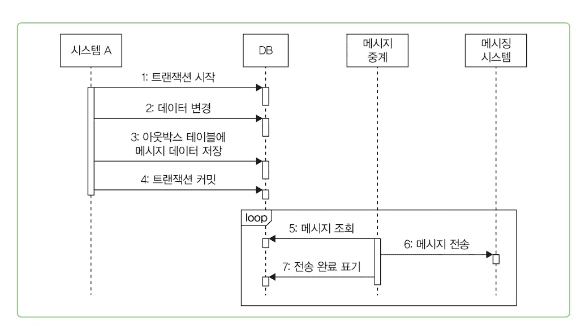
메시지 중계 서비스 구현
public void processMessages() {
// 이 메서드를 주기적으로 호출해서 메시지를 전송
// 아웃박스 테이블에서 대기 메시지 데이터를 순서대로 조회함
List<MessageData> waitingMessages = selectWaitingMessages();
for (MessageData m: waitingMessages) {
try {
sendMessage(m); // 메시지를 전송함
markDone(m.getId()); // 발송 완료 표시함
} catch (Exception ex) {
handleError(ex); // 메시지 발송에 실패한 경우 후속 처리함
break; // 에러가 났을 때 멈춤. 이유는 순서대로 발송하기 위함
}
}
}에러 발생 시 루프 종료 이유:
- 예를 들어 10개의 대기 메시지를 읽고 5번째 메시지 전송 중 에러가 발생
- 6번째부터 계속 전송하면 메시지가 생성된 순서와 다른 순서로 전송됨
- 메시지 전송 순서가 중요한 경우 이 점이 매우 중요
아웃박스 테이블 구조
| 칼럼 | 타입 | 설명 |
|---|---|---|
| id | bigint | 단순 증가 값(PK). 저장된 순서대로 증가하는 값을 사용한다. |
| messageId | varchar | 메시지 고유 ID(고유키) |
| messageType | varchar | LoginFailed OrderPlaced |
| payload | clob | 메시지 데이터 |
| status | varchar | WAITING(대기) DONE(완료) FAILED(실패함) |
| failCount | int | 실패 횟수 |
| occuredAt | timestamp | 메시지 발생 시간 |
| processedAt | timestamp | 메시지 처리 시간 |
| failedAt | timestamp | 마지막 실패 시간 |
payload
- JSON, XML 등
실패 상태 변경 기준
-
자동 변경: 실패 횟수 기반 (예: 5회 실패 시 FAILED로 변경)
-
수동 변경/모니터링: 실패 횟수 10회 초과 시 운영팀 알림, 수동으로 FAILED 변경
-
후속 조치: FAILED 상태 메시지는 시스템 간 데이터 불일치 방지를 위한 적절한 후속 조치 필요
-
디버깅:
memo또는remark컬럼 추가하여 실패 원인 기록주의사항:
- 메시지 전송 실패 시 즉시 FAILED로 변경하지 말 것
- 일시적 문제인 경우 몇 번 재시도 후 성공할 수 있음
status
EXCLUDED상태 추가 가능- 실패가 아닌 특정 메시지를 수동으로 전송 방지할 때 사용
4. 배치로 연동
배치 전송 개념 및 전형적 처리 방식
대량 데이터(10만 건)는 파일로 모아서 전송이 효율적
- 배치 전송은 데이터를 비동기로 연동하는 가장 전통적인 방법
- 메시징 시스템이 거의 실시간으로 데이터를 연동했다면, 배치는 일정 간격으로 데이터를 전송
- ex) 결제 승인 데이터를 모아서 다음날 아침에 보낸다던가
배치 처리의 전형적 과정
- DB에서 전송할 데이터를 조회.
- 조회한 결과를 파일로 기록.
- 파일을 연동 시스템에 전송.
- 파일 전송은 FTP, SFTP 같은 파일 전송 프로토콜 또는 SCP 명령어를 사용.
많이 사용한 파일 형식
구분자 기준
홍길동,25,개발자,서울
김철수,30,디자이너,부산
이영희,28,기획자,대구key-value
name=홍길동 age=25 job=개발자 city=서울
name=김철수 age=30 job=디자이너 city=부산
name=이영희 age=28 job=기획자 city=대구Json
{"name":"홍길동","age":25,"job":"개발자","city":"서울"}
{"name":"김철수","age":30,"job":"디자이너","city":"부산"}
{"name":"이영희","age":28,"job":"기획자","city":"대구"}파일 시스템 연동 시 정해야 할 항목
- 송수신 주체
- 전송 주기/시점
- 파일 전송 경로/파일명 규칙
송수신 주체 예시
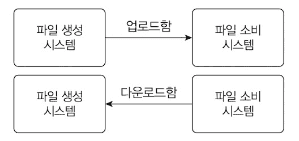
- 확장하는 서비스는 소비자에 맞춰 업로드해주는 경우가 많았음.
- 고객 시스템에 업로드해 준다.
- 보안을 이유로 시스템을 외부에 노출시키기 어려운 조직은 다운로드 방식을 택하기도 했음.
시간의 중요성
- 소비자는 특정 시점까지 데이터를 받아야 함.
- 배치 파일은 에러나 누락을 확인할 수 있는 여유시간을 확보하려고 근무가 시작되는 시간대에 전송하는 경우가 많았음.
- 경로, 파일명 충돌을 피하기 위해 규칙을 정했음.
파일 소비 프로세스 (생산자가 업로드해 줄 경우 소비자는 뭐 하냐?)
- 지정 경로에 파일 존재 확인함.
- 파일이 있으면 데이터 읽음.
- 파일 없으면 후처리.
- 읽어온 데이터를 시스템에 반영.
- 완료된 파일은 다른 폴더로 이동
파일 대신 API/DB 연동
- 데이터가 적거나 처리 항목이 적으면 API로 일괄 전송하는 방식을 쓰기도 함.
- 같은 조직 내에는 DB 읽기 전용권한을 주고 직접 접근하게 하기도 함.
재처리, 빈 파일 처리
- 파일 전송 실패 시 일정 시간 뒤 재전송 기능을 구현
- 수동 배치 실행 명령어나 API도 준비
- 전송할 데이터가 없을 때 파일을 생성하지 않으면, 고객사는 파일이 없는 원인을 혼란스러워하므로 빈 파일도 전송하게 개선했음.
5. CDC 이용하기
데이터베이스는 데이터가 변경되면 그 변경 내용을 통지하는 기능을 가진다.
모든 현대적인 데이터베이스(Oracle, MySQL 등)는 데이터의 변경 이력을 안정적으로 기록하고 관리하기 위한 트랜잭션 로그를 가지고 있음.
-> CDC는 바로 이 데이터베이스의 핵심 기능을 활용
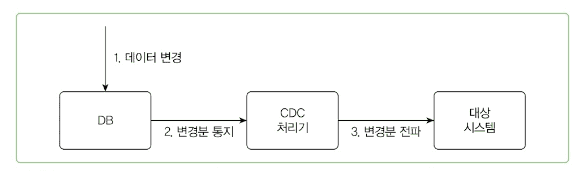
CDC는 애플리케이션과 완전히 분리되어, 데이터베이스의 트랜잭션 로그를 직접 읽는 방식으로 동작
전파 방법
1. 변경 데이터를 그대로 대상 시스템에 전파
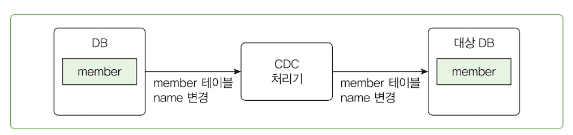
2. 변경 데이터를 가공/변환해서 전파

- 새로운 주문 데이터가 생성되거나 주문 상태가 '배송 중'으로 변경되면 통지 시스템에 전부 보낼 필요 없음.
- 주문ID랑 주문 상태만 보내면 됨.
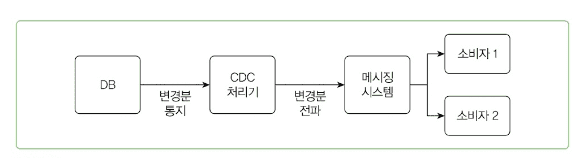
전파 대상
목적에 따라 DB, 메시징 시스템, API 등 선택 가능
에러 상황
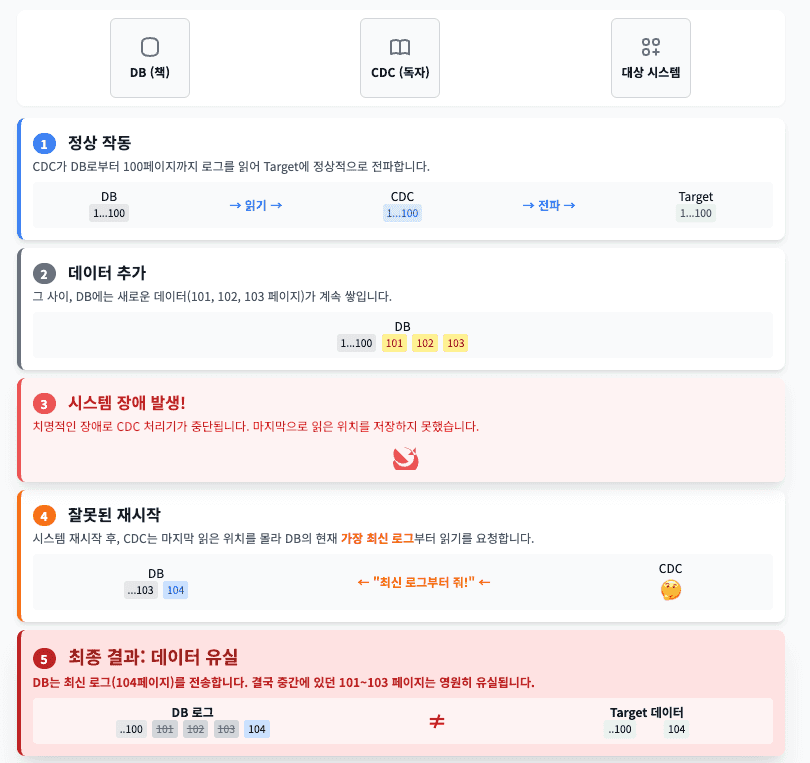
잘 처리된 상황

실제 사례
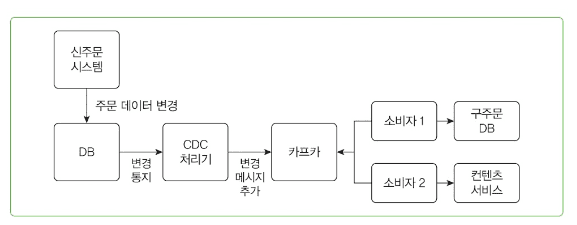
신규 주문 시스템이 평소처럼 주문을 처리하고 DB에 데이터를 저장/수정- CDC가 DB의 변경 내역을 실시간으로 감지합니다.
- CDC가 이 변경 데이터를
기존 주문 시스템이나콘텐츠 서비스가 이해할 수 있는 형태로 가공하여 메시지 큐(카프카)로 전달합니다. 기존 주문 시스템등은 메시지 큐에서 데이터를 가져가서 자신들의 시스템에 반영
구현
Debezium
- 역할: 실제 CDC의 핵심. 데이터베이스의 '가짜 복제본(replica)'처럼 위장하여 트랜잭션 로그를 읽어 들이는 커넥터
- 특징: MySQL, PostgreSQL, MongoDB, SQL Server 등 거의 모든 주요 데이터베이스를 지원
Kafka Connect
- 역할: Debezium 커넥터를 실행하고 관리하는 '실행 환경'
- 특징: Debezium을 안정적으로 실행하고, 장애가 발생하면 자동으로 재시작해줌.
Apache Kafka
- 역할: Debezium이 읽어 들인 변경 데이터를 저장하고 다른 시스템으로 전파
댓글