InnoDB 잠금 종류
InnoDB 스토리지 엔진은 레코드 기반 잠금 기능을 제공합니다.
락 에스컬레이션이란?
일부 DBMS에서는 잠금 개수가 많아지면 메모리 부족을 방지하기 위해 여러 개의 레코드 락을 페이지 락이나 테이블 락으로 자동 업그레이드합니다.
예: 1000개 레코드 락 → 1개 테이블 락으로 변환
InnoDB는 잠금 정보를 매우 작은 공간으로 관리하므로 락 에스컬레이션이 발생하지 않습니다.
일반 상용 DBMS와는 다르게 InnoDB에서는 다음과 같은 잠금 종류를 제공합니다.
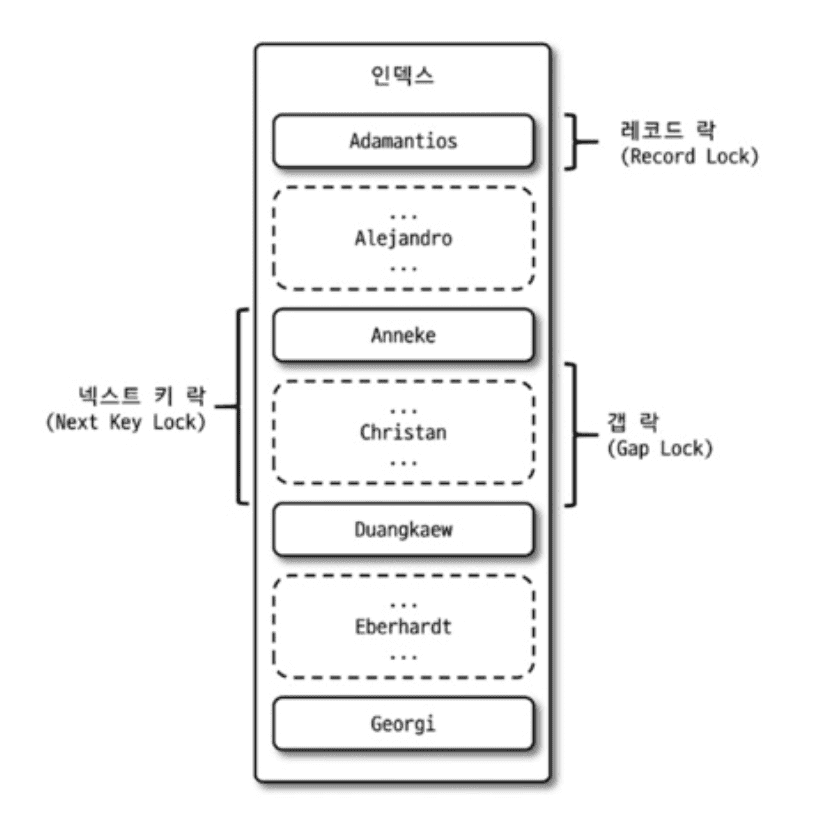
MySQL 락의 계층 구조
MySQL의 락은 크게 테이블 레벨 락과 레코드 레벨 락으로 나뉩니다.
MySQL 잠금 계층
1. 테이블 레벨 락
├─ 테이블 잠금 (LOCK TABLES)
├─ 메타데이터 락 (Metadata Lock)
├─ AUTO_INCREMENT 락
└─ 의도 락 (Intention Lock)
├─ IS (Intention Shared)
└─ IX (Intention Exclusive)
2. 레코드 레벨 락 (InnoDB 엔진)
├─ 레코드 락 (Record Lock)
├─ 갭 락 (Gap Lock)
├─ 넥스트 키 락 (Next-Key Lock)
└─ Insert Intention Lock테이블 레벨 락
테이블 전체에 영향을 미치는 락입니다. 테이블의 모든 레코드에 대한 접근을 제어합니다.
1. 테이블 잠금 (LOCK TABLES)
명시적으로 테이블 전체를 잠급니다.
LOCK TABLES users WRITE; -- 쓰기 잠금 (다른 커넥션은 읽기/쓰기 모두 대기)
-- 작업 수행
UNLOCK TABLES;
LOCK TABLES users READ; -- 읽기 잠금 (다른 커넥션은 쓰기만 대기)
-- 조회 작업
UNLOCK TABLES;특징:
- InnoDB에서는 거의 사용하지 않음
- 레코드 락으로 충분한 경합 제어 가능
- 전체 테이블을 잠그므로 동시성 매우 낮음
2. 메타데이터 락 (Metadata Lock)
테이블 구조를 변경하는 DDL 실행 시 자동으로 획득됩니다.
-- Connection 1
BEGIN;
SELECT * FROM users WHERE id = 1; -- 메타데이터 락 획득 (공유 락)
-- Connection 2
ALTER TABLE users ADD COLUMN age INT; -- 대기! (배타적 메타데이터 락 필요)
-- Connection 1
COMMIT; -- 메타데이터 락 해제 → Connection 2가 진행특징:
- 명시적으로 획득하는 것이 아니라 자동으로 획득
- 트랜잭션이 테이블을 사용하는 동안 테이블 구조 변경 방지
- 트랜잭션 종료 시 자동 해제
메타데이터 락의 2가지 종류:
| 락 타입 | 획득 상황 | 다른 트랜잭션 |
|---|---|---|
| 공유 메타데이터 락 | SELECT, INSERT, UPDATE, DELETE | 읽기/쓰기 가능, DDL 대기 |
| 배타적 메타데이터 락 | ALTER TABLE, DROP TABLE | 모든 작업 대기 |
3. AUTO_INCREMENT 락
AUTO_INCREMENT 컬럼의 값을 생성할 때 사용하는 테이블 레벨 락입니다.
-- Connection 1
INSERT INTO users (name) VALUES ('홍길동');
-- 1. AUTO_INCREMENT 락 획득 (테이블 레벨)
-- 2. id 값 생성 (예: 5)
-- 3. AUTO_INCREMENT 락 즉시 해제
-- 4. INSERT 계속 진행
-- Connection 2 (동시에)
INSERT INTO users (name) VALUES ('김철수');
-- AUTO_INCREMENT 락 획득 가능 (Connection 1이 이미 해제)
-- id 값 생성 (예: 6)특징:
- 매우 짧게 유지 (ID 생성 후 즉시 해제)
- INSERT 문장 완료를 기다리지 않음
- 테이블 레벨이지만 동시성에 거의 영향 없음
4. 의도 락 (Intention Lock)
레코드 락을 걸기 전에 이 테이블에 레코드 락을 걸 예정이라고 선언하는 테이블 레벨 락입니다.
-- Connection 1
BEGIN;
UPDATE users SET name = '홍길동' WHERE id = 1;
-- 1. 테이블에 IX 락 획득 (의도 표시)
-- 2. id=1 레코드에 X 락 획득
-- Connection 2 (다른 레코드)
UPDATE users SET name = '김철수' WHERE id = 2;
-- 1. 테이블에 IX 락 획득 (성공! IX끼리는 충돌 안 함)
-- 2. id=2 레코드에 X 락 획득 (성공! 다른 레코드)
-- Connection 3 (테이블 전체 잠금 시도)
LOCK TABLES users WRITE;
-- 대기! IX 락이 있으므로 테이블 잠금 불가의도 락의 종류:
| 락 타입 | 의미 | 실제 레코드 락 |
|---|---|---|
| IS (Intention Shared) | "공유 레코드 락을 걸 예정" | S (Shared) |
| IX (Intention Exclusive) | "배타적 레코드 락을 걸 예정" | X (Exclusive) |
의도 락의 역할:
-- 의도 락이 없다면?
-- LOCK TABLES users WRITE; 실행 시
-- 1. 모든 레코드를 일일이 확인 (30만 건)
-- 2. 하나라도 레코드 락이 있으면 실패
-- 3. 매우 느림!
-- 의도 락이 있으면?
-- 1. 테이블의 IX/IS 락만 확인
-- 2. 있으면 즉시 대기
-- 3. 매우 빠름!충돌 매트릭스:
| IS | IX | S (테이블 락) | X (테이블 락) | |
|---|---|---|---|---|
| IS | ✅ | ✅ | ✅ | ❌ |
| IX | ✅ | ✅ | ❌ | ❌ |
| S | ✅ | ❌ | ✅ | ❌ |
| X | ❌ | ❌ | ❌ | ❌ |
핵심:
- IS/IX끼리는 절대 충돌하지 않음 (여러 트랜잭션이 동시에 다른 레코드 잠금 가능)
- LOCK TABLES로 테이블 전체를 잠그려는 시도와만 충돌 (IS/IX가 있으면 테이블 전체 락 불가)
레코드 레벨 락
개별 레코드 또는 레코드 범위에 대한 락입니다. InnoDB 엔진만 제공합니다.
- 레코드 락 (Record Lock): 인덱스 레코드 하나만 잠금
- 갭 락 (Gap Lock): 레코드 사이의 간격만 잠금 (INSERT 방지)
- 넥스트 키 락 (Next-Key Lock): 레코드 락 + 갭 락 조합
- Insert Intention Lock: INSERT 시 사용하는 특수한 갭 락 (다른 Insert Intention Lock과 충돌하지 않음)
락 레벨별 정리
| 락 레벨 | 락 종류 | 자동/수동 | 용도 |
|---|---|---|---|
| 테이블 | LOCK TABLES | 수동 | 테이블 전체 잠금 (거의 안 씀) |
| 테이블 | 메타데이터 락 | 자동 | DDL 중 구조 변경 방지 |
| 테이블 | AUTO_INCREMENT | 자동 | ID 생성 동기화 |
| 테이블 | IS/IX | 자동 | 레코드 락 의도 표시 |
| 레코드 | Record Lock | 자동 | 특정 레코드 잠금 |
| 레코드 | Gap Lock | 자동 | 레코드 사이 INSERT 방지 |
| 레코드 | Next-Key Lock | 자동 | Record + Gap 조합 |
| 레코드 | Insert Intention | 자동 | INSERT 시 갭 락 (충돌 완화) |
레코드 락
레코드 자체만을 잠그는 것을 레코드 락(Record Lock, Record Only Lock)이라고 합니다. 다른 상용 DBMS의 레코드 락과 동일한 역할을 하지만, 중요한 차이점이 있습니다.
InnoDB는 레코드 자체가 아니라 인덱스의 레코드를 잠급니다.
- 인덱스가 하나도 없는 테이블이라도 내부적으로 자동 생성된 클러스터 인덱스를 이용해 잠금을 설정합니다.
- 레코드 자체를 잠그느냐, 인덱스를 잠그느냐는 상당히 크고 중요한 차이를 만들어냅니다.
인덱스 종류에 따른 잠금 범위
-- 1. 유니크 인덱스로 조회 (특정 레코드 1건만 존재)
UPDATE users SET name = '홍길동' WHERE id = 100;
-- 잠금: id=100 레코드만 잠금 (갭 락 없음)
-- 이유: 유니크이므로 id=100은 딱 1건만 존재, 중간에 끼어들 수 없음
-- 2. 일반 인덱스로 조회 (같은 값의 레코드가 여러 개 가능)
UPDATE users SET name = '홍길동' WHERE age = 30;
-- 잠금: age=30인 레코드들 + 그 사이사이 갭까지 잠금 (넥스트 키 락)
-- 이유: age=30인 레코드 사이에 새로운 age=30 레코드가 INSERT될 수 있음왜 차이가 나는가?
- 유니크 인덱스: 해당 값이 딱 1건만 존재 → 중간에 끼어들 여지가 없음 → 갭 락 불필요
- 일반 인덱스: 같은 값이 여러 개 → 그 사이에 새로운 레코드 INSERT 가능 → 갭 락 필요
INSERT, UPDATE, DELETE의 락 구조
각 DML 문은 서로 다른 락 조합을 사용합니다.
INSERT의 락 구조
테이블 레벨: IX (Intention Exclusive) 락
↓
갭 레벨: Insert Intention Lock (특수한 갭 락)
↓
레코드 레벨: X 락 (삽입된 레코드에)Insert Intention Lock은 갭 락의 일종이지만, 다른 Insert Intention Lock과 충돌하지 않습니다. 같은 갭에 여러 트랜잭션이 동시에 INSERT할 수 있습니다. 단, 삽입 위치가 달라야 합니다.
-- id가 1, 5, 10인 레코드가 있을 때
-- 트랜잭션 A
INSERT INTO users (id) VALUES (3);
-- IX 락 (테이블) + Insert Intention Lock (1~5 갭) + X 락 (id=3)
-- 트랜잭션 B (동시에)
INSERT INTO users (id) VALUES (7);
-- IX 락 (테이블) + Insert Intention Lock (5~10 갭) + X 락 (id=7)
-- → 충돌 없음, 둘 다 진행UPDATE/DELETE의 락 구조
테이블 레벨: IX (Intention Exclusive) 락
↓
레코드 레벨: Next-Key Lock (X) = Record Lock + Gap LockUPDATE와 DELETE는 Next-Key Lock을 사용하여 레코드와 그 앞의 갭을 함께 잠급니다.
-- id가 1, 5, 10인 레코드가 있을 때
UPDATE users SET name = 'test' WHERE id = 5;
-- 락 범위
Record Lock: id = 5 (X 락)
Gap Lock: (1, 5) 구간
-- 즉, Next-Key Lock = (1, 5] 범위DML별 락 비교
| 연산 | 테이블 락 | 레코드 락 |
|---|---|---|
| INSERT | IX | Insert Intention Lock + X (삽입 레코드) |
| UPDATE | IX | Next-Key Lock (X) = Record + Gap |
| DELETE | IX | Next-Key Lock (X) = Record + Gap |
| SELECT ... FOR UPDATE | IX | Next-Key Lock (X) |
갭 락
갭 락(Gap Lock)은 레코드 자체가 아니라 레코드와 바로 인접한 레코드 사이의 간격만을 잠급니다.
갭 락의 역할은 레코드와 레코드 사이의 간격에 새로운 레코드가 생성(INSERT)되는 것을 제어하는 것입니다.
갭 락 그 자체보다는 다음에 설명할 넥스트 키 락의 일부로 자주 사용됩니다.
넥스트 키 락
레코드 락 + 갭 락 = 넥스트 키 락(Next Key Lock)
왜 필요한가?
MySQL의 복제(Replication) 환경에서 Master와 Replica 서버의 데이터 일관성을 보장하기 위해 필요합니다.
-- Master 서버
START TRANSACTION;
DELETE FROM orders WHERE price >= 10000; -- 현재 10건 삭제
-- 만약 갭 락이 없다면?
-- 다른 트랜잭션에서 INSERT INTO orders VALUES (11, 15000); 실행 가능
COMMIT;
-- 바이너리 로그에 기록됨: "DELETE FROM orders WHERE price >= 10000"문제 상황
- 갭 락이 없으면: DELETE 실행 중에 price=15000인 새 주문이 INSERT될 수 있음
- Replica 서버에서 재생 시: 이 INSERT가 없는 상태에서 DELETE 실행
- 결과: Master는 11건 삭제, Replica는 10건 삭제 → 데이터 불일치
넥스트 키 락으로 해결
- DELETE 실행 시 price >= 10000 범위의 레코드 + 갭까지 모두 잠금
- 그 사이에 INSERT 불가능
- Master와 Replica의 결과가 동일하게 보장됨
바이너리 로그 포맷 차이
STATEMENT 포맷: SQL 문장 자체를 기록-- Master에서 실행 DELETE FROM orders WHERE price >= 10000; -- 바이너리 로그에 기록 "DELETE FROM orders WHERE price >= 10000" -- Replica에서 이 SQL을 그대로 재실행 -- 문제: Replica 실행 시점에 Master와 데이터가 다를 수 있음 -- 해결: 넥스트 키 락으로 INSERT 차단 필요ROW 포맷: 변경된 행의 실제 데이터를 기록
-- Master에서 실행 DELETE FROM orders WHERE price >= 10000; -- 바이너리 로그에 기록 "id=5, price=10000 삭제" "id=7, price=12000 삭제" "id=9, price=15000 삭제" -- Replica에서 정확히 이 행들만 삭제 -- 중간에 INSERT가 있어도 상관없음 (삭제할 행이 명확히 지정됨) -- 해결: 넥스트 키 락 불필요ROW 포맷은 삭제할 행을 명확히 지정하므로 갭 락이 불필요하여 성능이 향상됩니다.
자동 증가 락
AUTO_INCREMENT 락이란?
AUTO_INCREMENT 컬럼
JPA의 @GeneratedValue(strategy = GenerationType.IDENTITY)을 사용할 때, 여러 커넥션에서 동시에 INSERT해도 ID 값이 중복되지 않도록 보장하는 테이블 수준의 잠금입니다.
-- 테이블 정의
CREATE TABLE users (
id BIGINT AUTO_INCREMENT PRIMARY KEY, -- JPA @GeneratedValue(IDENTITY)
name VARCHAR(50)
);
-- 동시에 두 INSERT 실행
-- Connection 1
INSERT INTO users (name) VALUES ('홍길동'); -- id=1 할당
-- Connection 2
INSERT INTO users (name) VALUES ('김철수'); -- id=2 할당 (중복 없이)특징
- INSERT/REPLACE에서만 사용 (UPDATE/DELETE는 무관)
- ID 값을 가져오는 순간만 잠금 후 즉시 해제
- 트랜잭션과 무관하게 작동
락 방식의 차이
AUTO_INCREMENT 락 vs 경량 래치(Mutex)
AUTO_INCREMENT 락: INSERT 문장이 완료될 때까지 락 유지 (느림)
경량 래치(Mutex): ID 값만 가져가면 즉시 해제 (빠름, 뮤텍스라고도 함)
-- AUTO_INCREMENT 락 사용 시
INSERT INTO users (name) SELECT name FROM temp_users; -- 1000건
-- 1. 락 획득
-- 2. ID 1~1000 할당
-- 3. 1000건 모두 INSERT 완료
-- 4. 락 해제 ← INSERT가 끝나야 해제 (느림)
-- 경량 래치 사용 시
INSERT INTO users (name) VALUES ('홍길동');
-- 1. 래치 획득
-- 2. ID=5 할당받음
-- 3. 래치 즉시 해제 ← INSERT 완료 전에 해제 (빠름)
-- 4. INSERT 계속 진행
-- → 다른 커넥션이 바로 ID=6 받아갈 수 있음innodb_autoinc_lock_mode 설정(MySQL 8.0 기준)
| 모드 | 잠금 방식 | 성능 | 연속성 |
|---|---|---|---|
| 0 | 모든 INSERT에 락 사용 | 느림 | 완벽 보장 |
| 1 | 단순 INSERT는 래치, 대량은 락 | 중간 | 한 문장만 |
| 2 (기본값) | 모든 INSERT에 래치만 | 빠름 | 보장 안 됨 |
각 모드별 동작 예시
-- 모드 1: 단순 INSERT (건수 예측 가능)
INSERT INTO users (name) VALUES ('홍길동'); -- 경량 래치 사용 (빠름)
-- 모드 1: 대량 INSERT (건수 예측 불가)
INSERT INTO users (name) SELECT name FROM temp_users; -- AUTO_INCREMENT 락 사용 (느림)
-- 모드 2: 모든 경우
INSERT INTO users ... -- 항상 경량 래치 (가장 빠름, 하지만 연속성 보장 안 됨)ID 연속성이 보장되지 않는다는 의미
-- Connection 1이 대량 INSERT 시작 INSERT INTO users SELECT * FROM temp_users; -- 1000건 -- 모드 1 (연속성 보장): -- 1. Connection 1이 AUTO_INCREMENT 락 획득 -- 2. id=1~1000 모두 할당받음 -- 3. 1000건 INSERT 완료 -- 4. 락 해제 -- → Connection 1이 끝날 때까지 다른 커넥션은 대기 -- → 결과: Connection 1은 id=1~1000을 연속으로 받음 -- 모드 2 (연속성 보장 안 됨): -- 1. Connection 1: id=1 받음 → 래치 즉시 해제 -- 2. Connection 1: id=2 받음 → 래치 즉시 해제 -- 3. Connection 2: id=3 받음 → 래치 즉시 해제 (끼어듦!) -- 4. Connection 1: id=4 받음 → 래치 즉시 해제 -- 5. Connection 2: id=5 받음 → 래치 즉시 해제 (또 끼어듦!) -- 6. Connection 1: id=6 받음... -- → Connection 1은 id=1,2,4,6,7... (중간이 빠짐) -- → Connection 2는 id=3,5,8,10... (끼어든 것들)
핵심: 모드 2에서는 대량 INSERT 중간에 다른 커넥션이 끼어들어 ID를 가져갈 수 있어서, 한 INSERT 문장이 연속된 ID를 받지 못합니다.
MySQL 8.0 기본값이 2인 이유
ROW 포맷은 실제 데이터를 기록하므로 ("id=1 삭제", "id=3 삭제") ID 순서가 뒤섞여도 복제에 문제가 없습니다.
STATEMENT 포맷 사용 시 주의: 모드 2에서는 Master와 Replica의 AUTO_INCREMENT 값이 달라질 수 있으므로 모드 1로 변경 권장
왜 INSERT 실패 시 ID가 건너뛰는가?
AUTO_INCREMENT는 테이블 전체에서 공유하는 하나의 카운터입니다.
-- AUTO_INCREMENT 카운터 = 5 (테이블 전체 공유)
-- Connection 1
-- 1. 래치 획득 → 카운터에서 5 받음 → 카운터 6으로 증가 → 래치 해제
-- 2. INSERT 실행 중...
-- Connection 2 (동시에 실행)
-- 1. 래치 획득 → 카운터에서 6 받음 → 카운터 7으로 증가 → 래치 해제
-- 2. INSERT 완료
-- Connection 3
-- 1. 래치 획득 → 카운터에서 7 받음 → 카운터 8으로 증가 → 래치 해제
-- 2. INSERT 완료
-- Connection 1
-- 3. INSERT 실패! (중복 이메일)
-- 4. 카운터를 5로 되돌리려면?
-- → 이미 카운터는 8
-- → 다른 커넥션이 6, 7 사용 중
-- → 되돌리면 6, 7과 충돌! (매우 복잡)그래서 실패해도 카운터는 되돌리지 않고, id=5는 영구 건너뛴 채로 단순하게 처리합니다.
인덱스와 잠금
InnoDB의 잠금과 인덱스는 상당히 중요한 연관 관계가 있습니다. InnoDB의 잠금은 레코드를 잠그는 것이 아니라 인덱스를 잠그는 방식으로 처리됩니다.
즉, 변경해야 할 레코드를 찾기 위해 검색한 인덱스의 레코드를 모두 락을 걸어야 합니다.
예제: 인덱스와 잠금 범위
employees 테이블에 다음과 같은 인덱스가 있다고 가정하겠습니다.
-- ix_firstname 인덱스 구성
KEY ix_firstname (first_name)데이터 분포
-- first_name='Georgi'인 사원: 253명
mysql> SELECT COUNT(*) FROM employees WHERE first_name='Georgi';
+----------+
| 253 |
+----------+
-- first_name='Georgi'이고 last_name='Klassen'인 사원: 1명
mysql> SELECT COUNT(*) FROM employees WHERE first_name='Georgi' AND last_name='Klassen';
+----------+
| 1 |
+----------+UPDATE 쿼리 실행
mysql> UPDATE employees
SET hire_date=NOW()
WHERE first_name='Georgi' AND last_name='Klassen';결과 분석
- 실제로 업데이트되는 레코드: 1건
- 실제로 잠금이 걸리는 레코드: 253건
왜 253건이 잠기는가?
- 인덱스를 이용할 수 있는 조건은
first_name='Georgi' last_name컬럼은 인덱스에 없음- 따라서
first_name='Georgi'인 레코드 253건을 모두 검색하면서 잠금 - 각 레코드에서
last_name='Klassen'조건을 추가로 필터링
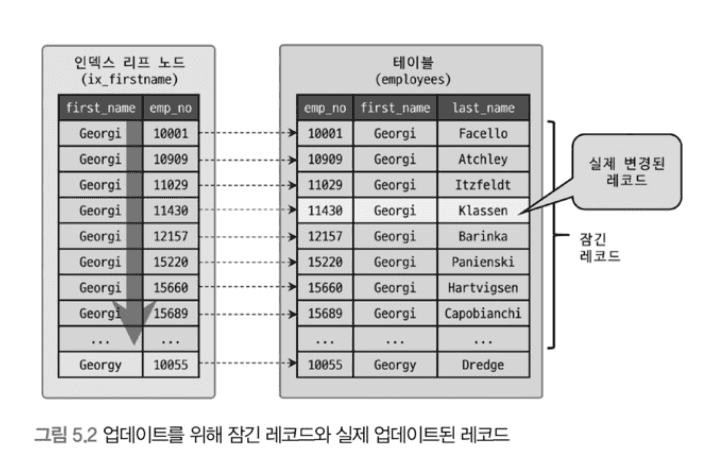
인덱스가 하나도 없다면?
-- 사용자가 생성한 인덱스가 없어도 InnoDB는 자동으로 클러스터 인덱스를 생성
CREATE TABLE test (
id INT, -- PRIMARY KEY 없음
name VARCHAR(50)
);
UPDATE test SET name = '홍길동' WHERE name = '김철수';
-- 동작:
-- 1. 클러스터 인덱스(내부적으로 자동 생성)로 풀 스캔
-- 2. 모든 레코드를 검색하면서 잠금
-- 3. name='김철수' 조건에 맞는 레코드만 UPDATE
-- 4. 결과: 30만 건 모두 잠금 (1건만 UPDATE해도!)클러스터 인덱스 자동 생성 규칙
PRIMARY KEY가 있으면 그것을 클러스터 인덱스로 사용
PRIMARY KEY가 없으면 첫 번째 UNIQUE NOT NULL 인덱스를 사용
둘 다 없으면 InnoDB가 숨겨진 6바이트 Row ID를 자동 생성하여 클러스터 인덱스로 사용
문제: 자동 생성된 Row ID 클러스터 인덱스는 WHERE 조건에 사용할 수 없어서, 결국 풀 스캔하며 모든 레코드에 잠금을 걸게 됩니다.
인덱스 설계의 중요성
UPDATE 문장을 위해 적절한 인덱스가 준비되어 있지 않다면 클라이언트 간의 동시성이 상당히 떨어집니다.
한 세션에서 UPDATE 작업을 하는 중에는 다른 클라이언트는 그 테이블을 업데이트하지 못하고 기다려야 하는 상황이 발생합니다.
레코드 수준의 잠금 확인 및 해제
InnoDB 스토리지 엔진을 사용하는 테이블의 레코드 수준 잠금은 테이블 수준 잠금보다 조금 더 복잡합니다.
- 테이블 잠금: 잠금의 대상이 테이블 자체라 쉽게 문제의 원인을 발견하고 해결 가능
- 레코드 잠금: 각각의 레코드에 잠금이 걸리므로 자주 사용되지 않으면 오랜 시간 잠겨 있어도 잘 발견되지 않음
MySQL 버전별 잠금 조회 방법
- MySQL 5.1 이전: 레코드 잠금에 대한 메타 정보(딕셔너리 테이블)를 제공하지 않아 어려움
- MySQL 5.1 ~ 7.x:
information_schema의INNODB_TRX,INNODB_LOCKS,INNODB_LOCK_WAITS테이블로 확인 - MySQL 8.0 이상:
performance_schema의data_locks와data_lock_waits테이블로 대체
강제 해제는 KILL 명령어로 프로세스를 종료하면 됩니다.
잠금 시나리오 예제
| 커넥션 1 | 커넥션 2 | 커넥션 3 |
|---|---|---|
BEGIN; |
||
UPDATE employees SET birth_date=NOW() WHERE emp_no=100001; |
||
UPDATE employees SET hire_date=NOW() WHERE emp_no=100001; |
||
UPDATE employees SET hire_date=NOW(), birth_date=NOW() WHERE emp_no=100001; |
프로세스 목록 확인
mysql> SHOW PROCESSLIST;+----+------+-----------+-------+---------+------+----------+------------------------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------+-------+---------+------+----------+------------------------------------------------------------------+
| 17 | root | localhost | testdb| Sleep | 607 | | NULL |
| 18 | root | localhost | testdb| Query | 22 | updating | UPDATE employees SET hire_date=NOW() WHERE emp_no=100001 |
| 19 | root | localhost | testdb| Query | 21 | updating | UPDATE employees SET hire_date=NOW(), birth_date=NOW() WHERE ... |
+----+------+-----------+-------+---------+------+----------+------------------------------------------------------------------+결과 해석
-
17번 스레드:
Sleep상태, 607초 동안 유휴 상태- 트랜잭션을 시작(
BEGIN)하고 UPDATE 후 커밋하지 않은 상태 - 현재 실행 중인 쿼리가 없어서
NULL로 표시 - 이 스레드가 잠금을 보유하고 있어서 다른 스레드들이 대기 중
- 트랜잭션을 시작(
-
18번 스레드:
updating상태, 22초 동안 대기- 17번 스레드가 잠근 레코드를 UPDATE하려고 시도
- 잠금을 획득하지 못해 대기 중
-
19번 스레드:
updating상태, 21초 동안 대기- 17번과 18번 스레드가 잠근 레코드를 UPDATE하려고 시도
- 두 스레드 모두 완료될 때까지 대기 중
잠금 대기 순서 확인
performance_schema의 data_locks 테이블과 data_lock_waits 테이블을 조인하여 잠금 대기 순서를 확인합니다.
mysql> SELECT
r.trx_id waiting_trx_id,
r.trx_mysql_thread_id waiting_thread,
r.trx_query waiting_query,
b.trx_id blocking_trx_id,
b.trx_mysql_thread_id blocking_thread,
b.trx_query blocking_query
FROM performance_schema.data_lock_waits w
INNER JOIN information_schema.innodb_trx b
ON b.trx_id = w.blocking_engine_transaction_id
INNER JOIN information_schema.innodb_trx r
ON r.trx_id = w.requesting_engine_transaction_id;+-------------+----------------+------------------+----------------+------------------+----------------+
| waiting_trx | waiting_thread | waiting_query | blocking_trx | blocking_thread | blocking_query |
| _id | | | _id | | |
+-------------+----------------+------------------+----------------+------------------+----------------+
| 11990 | 19 | UPDATE employees | 11984 | 17 | NULL |
| 11990 | 19 | UPDATE employees | 11984 | 17 | NULL |
| 11989 | 18 | UPDATE employees | 11984 | 17 | NULL |
+-------------+----------------+------------------+----------------+------------------+----------------+결과 분석
- 18번 스레드는 17번 스레드를 기다리고 있음
- 19번 스레드는 17번 스레드와 18번 스레드를 기다리고 있음
잠금 대기 큐
- 17번 스레드가 잠금을 해제
- 18번 스레드가 잠금을 획득하고 UPDATE 완료 후 잠금 해제
- 19번 스레드가 UPDATE 실행 가능
상세 잠금 정보 확인
17번 스레드가 어떤 잠금을 가지고 있는지 더 상세히 확인하려면 performance_schema의 data_locks 테이블을 조회합니다.
mysql> SELECT * FROM performance_schema.data_locks\G*************************** 1. row ***************************
ENGINE: INNODB
...
LOCK_TYPE: TABLE
LOCK_MODE: IX
LOCK_STATUS: GRANTED
LOCK_DATA: NULL
*************************** 2. row ***************************
ENGINE: INNODB
...
LOCK_TYPE: RECORD
LOCK_MODE: X,REC_NOT_GAP
LOCK_STATUS: GRANTED
LOCK_DATA: 100001결과 해석
17번 스레드가 2개의 락을 동시에 보유하고 있습니다:
1행: 테이블에 IX 잠금 (의도 표시)
LOCK_TYPE: TABLELOCK_MODE: IX(Intention Exclusive)- 역할: "이 테이블에 레코드 락을 걸 예정"이라고 선언
2행: 실제 레코드에 쓰기 잠금
LOCK_TYPE: RECORDLOCK_MODE: X,REC_NOT_GAP- 역할:
emp_no=100001레코드를 실제로 잠금
IX 잠금의 역할
InnoDB는 레코드 락을 걸 때 항상 2단계로 진행합니다:
먼저 테이블에 IX 락을 걸어서 의도를 표시
그 다음 실제 레코드에 레코드 락을 걸음
IX 락은 실제 데이터 접근을 막지 않고,
LOCK TABLES같은 테이블 전체 락과의 충돌만 방지합니다.
다른 레코드는 동시에 접근 가능한가?
인덱스가 있는 경우
-- Connection 1
BEGIN;
UPDATE employees SET salary = 5000 WHERE emp_no = 100001;
-- IX 락 + emp_no=100001 레코드 락만
-- Connection 2 (다른 레코드)
UPDATE employees SET salary = 6000 WHERE emp_no = 100002;
-- 성공! 동시 실행 가능
-- Connection 3 (같은 레코드)
UPDATE employees SET salary = 7000 WHERE emp_no = 100001;
-- 대기! emp_no=100001은 Connection 1이 보유 중인덱스가 없는 경우
CREATE TABLE test (
id INT, -- PRIMARY KEY 없음
name VARCHAR(50)
);
-- Connection 1
BEGIN;
UPDATE test SET salary = 5000 WHERE name = '홍길동';
-- IX 락 + 전체 레코드 락 (30만 건)
-- Connection 2 (다른 조건)
UPDATE test SET salary = 6000 WHERE name = '김철수';
-- 대기! '김철수' 레코드도 이미 Connection 1이 잠금
-- Connection 3 (전혀 다른 조건)
UPDATE test SET age = 30 WHERE name = '박영희';
-- 대기! '박영희' 레코드도 이미 Connection 1이 잠금핵심: IX 락끼리는 충돌하지 않습니다. 실제 충돌은 레코드 락 레벨에서 발생합니다. 하지만 인덱스가 없으면 전체 레코드를 잠그므로 WHERE 조건이 달라도 모두 대기하게 됩니다.
잠금 강제 해제
17번 스레드가 잠금을 가진 상태에서 상당히 오래 시간 멈춰 있다면 다음과 같이 강제 종료하여 나머지 UPDATE 명령들이 실행되도록 할 수 있습니다.
mysql> KILL 17;
댓글